Random numbers
In my Arduino projects, I had been using the typical pattern of seeding the pseudo random number generator with a reading from an analog pin like randomSeed(analogRead(A0)). Anecdotally, the results seemed nowhere near random. If I had a program that selected from three modes, the first mode would be the selected mode the majority of the time.
I knew the analog pin value distribution is usually pretty clumped around 400 and certainly within the range 0 to 512 or 1024 depending on the board and setup. The randomSeed() documentation
does not say whether there is a relationship between the position of the seed value within the accepted range and the resulting random values. For example, are the results of 10 different seeds within the range 400 to 500 less random than the results of 10 different seeds within the full int range 0 to 4,294,967,295 (on SAMD based boards; 65,535 on ATmega)?
That test will have to wait for another day, as I’ve already gotten too distracted with ways to get a more random seed. I tried Arduino forum user gardner‘s sample code that repeatedly uses 3 bits from an analog read to combine and shuffle into a full int. I put that into the following sketch and ran it till I got 100,000 results.
void setup() {
while(!Serial);
Serial.begin(9600);
}
void loop() {
Serial.println(get_seed(A5));
}
uint32_t get_seed(int pin)
{
uint16_t aread;
union {
uint32_t as_uint32_t;
uint8_t as_uint8_t[4];
} seed;
uint8_t i, t;
/* "aread" shifts 3 bits each time and the shuffle
* moves bytes around in chunks of 8. To ensure
* every bit is combined with every other bit,
* loop 3 x 8 = 24 times.
*/
for (i = 0; i < 24; i++) {
/* Shift three bits of A2D "noise" into aread.
*/
aread <<= 3;
aread |= analogRead(pin) & 0x7;
/* Now shuffle the bytes of the seed
* and xor our new set of bits onto the
* the seed.
*/
t = seed.as_uint8_t[0];
seed.as_uint8_t[0] = seed.as_uint8_t[3];
seed.as_uint8_t[3] = seed.as_uint8_t[1];
seed.as_uint8_t[1] = seed.as_uint8_t[2];
seed.as_uint8_t[2] = t;
seed.as_uint32_t ^= aread;
}
return(seed.as_uint32_t);
}
Short of doing statistical tests, they look pretty uniform to me.
Spread over two buckets using floor(x/4294967295, 0.5):

seed-distribution-0.5.png
Spread over 10 buckets using floor(x/4294967295, 0.1):
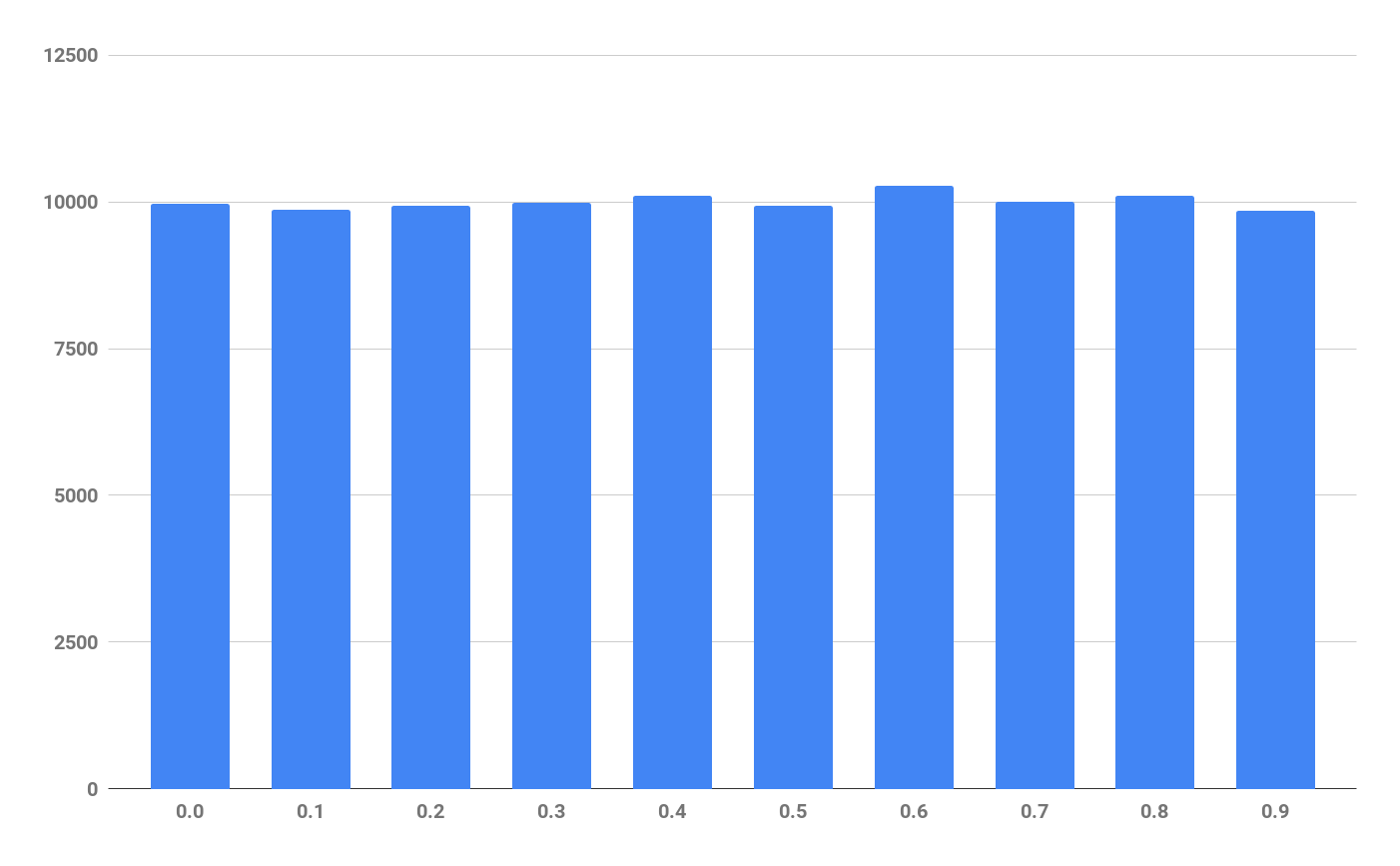
seed-distribution-0.1.png
Spread over 100 buckets using floor(x/4294967295, 0.01):
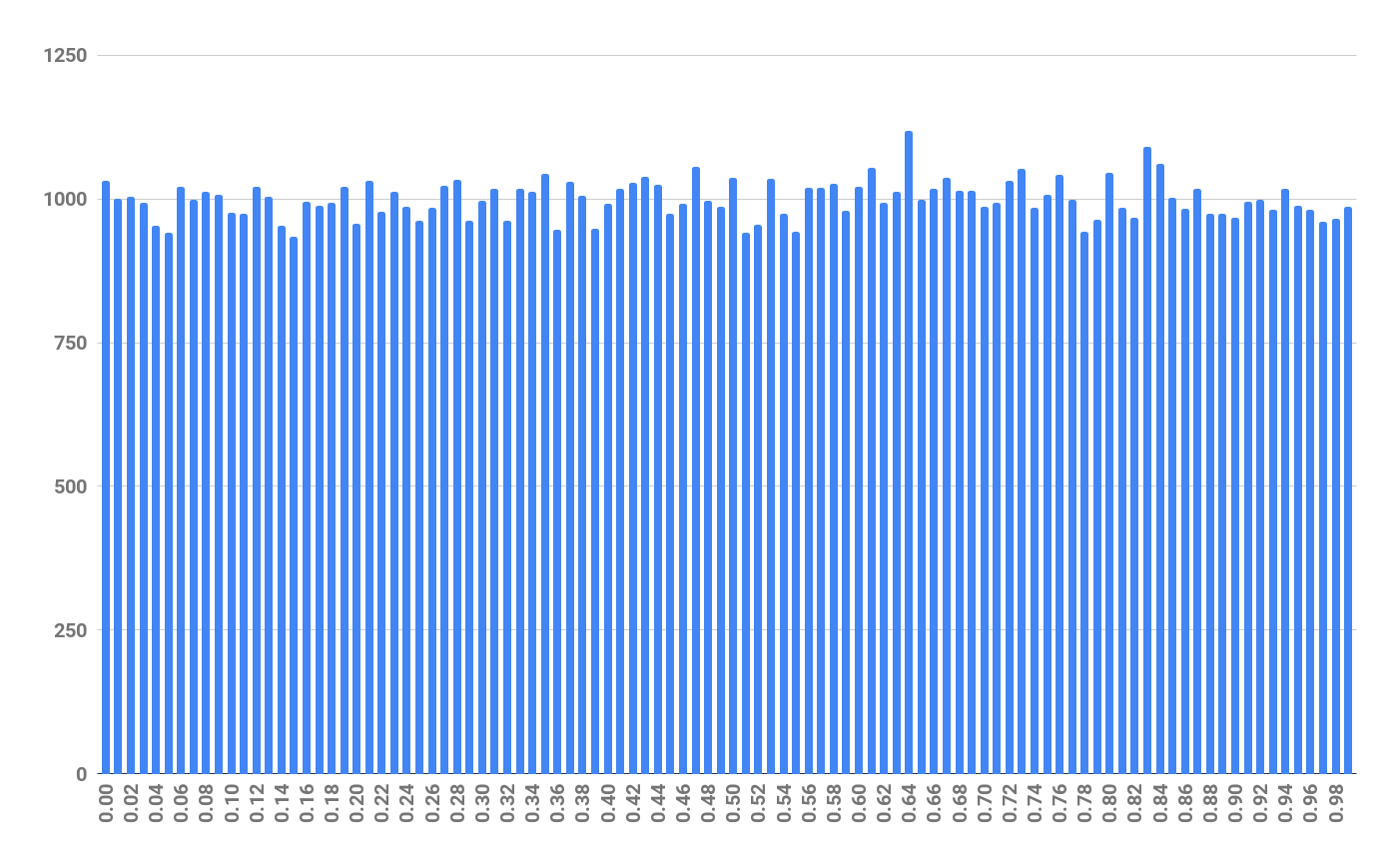
seed-distribution-0.01.png
Plotting all 100,000 values, the vast majority occur once:
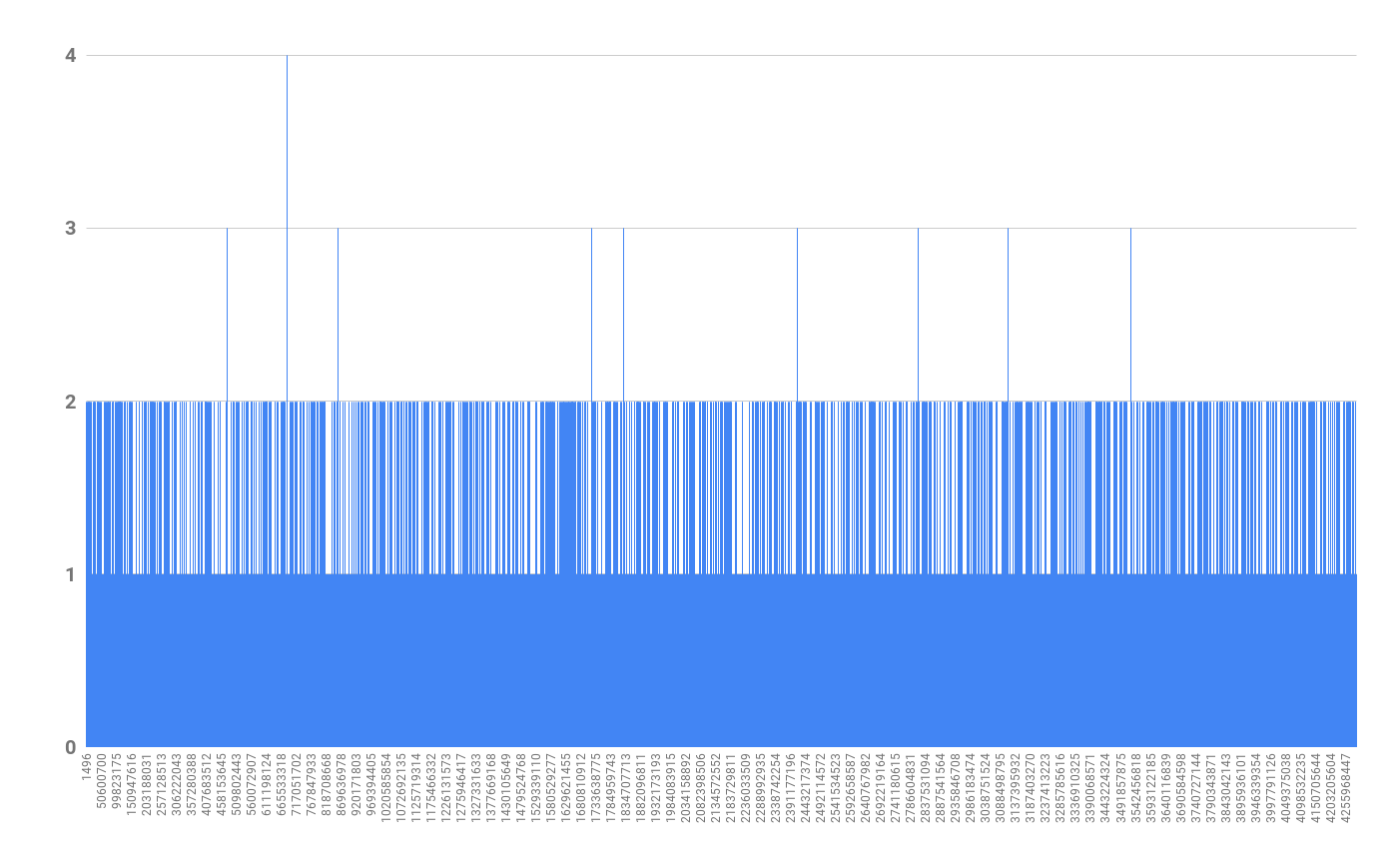
seed-distribution-full.png